Formuła do obliczenia Z-Score
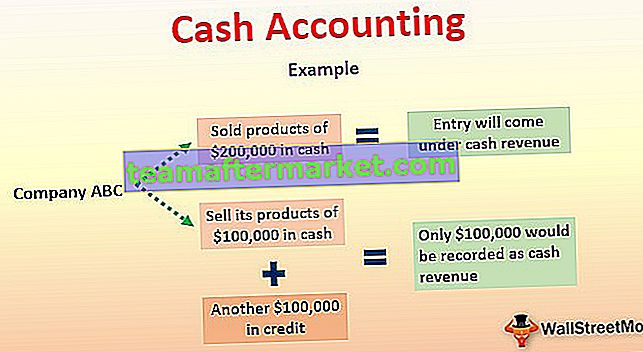
Z-score surowych danych odnosi się do wyniku wygenerowanego przez pomiar, ile odchyleń standardowych powyżej lub poniżej średniej populacji stanowi dane, co pomaga w testowaniu rozważanej hipotezy. Innymi słowy, jest to odległość punktu danych od średniej populacji, wyrażona jako wielokrotność odchylenia standardowego.
- Z-score waha się w zakresie od -3-krotności odchylenia standardowego (skrajna lewa strona rozkładu normalnego) do +3-krotności odchylenia standardowego (skrajna prawa rozkład normalny).
- Z-score ma średnią 0 i odchylenie standardowe 1.
Równanie wyniku z punktu danych oblicza się przez odjęcie średniej populacji od punktu danych (określanego jako x ), a następnie wynik dzieli się przez odchylenie standardowe populacji. Matematycznie jest reprezentowany jako
Punktacja Z = (x - μ) / ơ
gdzie
- x = punkt danych
- μ = średnia
- ơ = odchylenie standardowe
Obliczanie Z Score (krok po kroku)
Równanie dla wyniku z punktu danych można wyprowadzić, wykonując następujące kroki:
- Krok 1: Po pierwsze, określ średnią zbioru danych na podstawie punktów danych lub obserwacji, które są oznaczone x i , podczas gdy całkowita liczba punktów danych w zestawie danych jest oznaczona przez N.

- Krok 2: Następnie określ odchylenie standardowe populacji na podstawie średniej populacji μ, punktów danych x i oraz liczby punktów danych w populacji N.

- Krok 3: Na koniec wynik-z jest wyliczany przez odjęcie średniej od punktu danych, a następnie wynik jest dzielony przez odchylenie standardowe, jak pokazano poniżej.


Przykłady
Możesz pobrać ten szablon Z Score Formula Excel tutaj - Z Score Formula Excel TemplatePrzykład 1
Weźmy na przykład grupę 50 uczniów, którzy w zeszłym tygodniu napisali test z przedmiotów ścisłych. Dzisiaj jest dzień wyników, a wychowawca klasy powiedział, że Jan uzyskał 93 punkty w teście, podczas gdy średni wynik klasy wynosił 68. Określ wynik z dla oceny Johna, jeśli odchylenie standardowe wynosi 13.
Rozwiązanie:
Dany,
- Wynik testu Johna, x = 93
- Średnia, μ = 68
- Odchylenie standardowe, ơ = 13

Dlatego wynik z dla wyniku testu Johna można obliczyć przy użyciu powyższego wzoru, jak:

Z = (93 - 68) / 13
Wynik Z wyniesie -

Punktacja Z = 1,92
Dlatego wynik Johna Ztest jest o 1,92 odchylenie standardowe powyżej średniej oceny klasy, co oznacza, że 97,26% klasy (49 uczniów) uzyskało mniej punktów niż John.
Przykład nr 2
Weźmy inny szczegółowy przykład 30 uczniów (ponieważ test z nie jest odpowiedni dla mniej niż 30 punktów danych), którzy pojawili się na teście klasowym. Określ wynik testu z dla czwartego ucznia na podstawie ocen uzyskanych przez uczniów na 100 - 55, 67, 84, 65, 59, 68, 77, 95, 88, 78, 53, 81, 73, 66 65, 52, 54, 83, 86, 94, 85, 72, 62, 64, 74, 82, 58, 57, 51, 91.
Rozwiązanie:
Dany,
- x = 65,
- 4. student uzyskał wynik = 65,
- Liczba punktów danych, N = 30.
Średnia = (55 + 67 + 84 + 65 + 59 + 68 + 77 + 95 + 88 + 78 + 53 + 81 + 73 + 66 + 65 + 52 + 54 + 83 + 86 + 94 + 85 + 72 + 62 + 64 + 74 + 82 + 58 + 57 + 51 + 91) / 30
Średnia = 71,30
Teraz odchylenie standardowe można obliczyć za pomocą wzoru, jak pokazano poniżej,

ơ = 13,44
Dlatego wynik Z czwartego ucznia można obliczyć za pomocą powyższego wzoru jako:
Z = (x - x) / s
- Z = (65–30) / 13,44
- Z = -0,47
Zatem wynik czwartego ucznia jest o 0,47 odchylenia standardowego poniżej średniej oceny klasy, co oznacza, że 31,92% klasy (10 uczniów) uzyskało mniej wyników niż czwarty uczeń według tabeli z-score.
Wynik Z w programie Excel (z szablonem programu Excel)
Teraz weźmy przypadek wspomniany w przykładzie 2, aby zilustrować pojęcie z-score w poniższym szablonie programu Excel.
Poniżej podano dane do obliczenia Z Score


Możesz odnieść się do podanego arkusza Excela poniżej, aby uzyskać szczegółowe obliczenia statystyk testu wzoru Z Score.
Trafność i zastosowania
Z punktu widzenia testowania hipotez, z-score jest bardzo ważnym pojęciem do zrozumienia, ponieważ jest wykorzystywane do sprawdzania, czy statystyka testowa mieści się w dopuszczalnym zakresie wartości. Z-score jest również używany do standaryzacji danych przed analizą, obliczenia prawdopodobieństwa wyniku lub porównania dwóch lub więcej punktów danych, które pochodzą z różnych rozkładów normalnych. Jeśli są stosowane prawidłowo, wyniki z-score są różne w różnych polach.